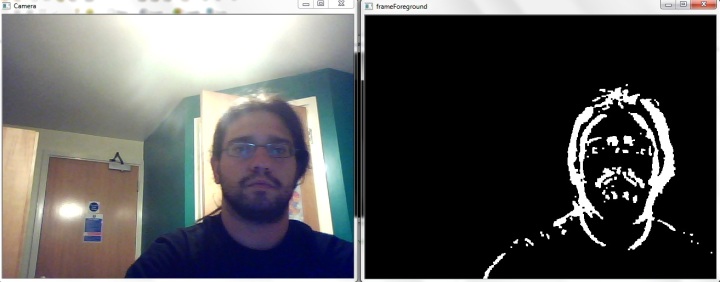
Background is a map of the sensory (visual) information encoded at much longer time constant, e.g., much slower changing. In other words, objects that are static or sustained are encoded into the background.
Background image,  can be computed per pixel as:
can be computed per pixel as:

Where  is in the range of [0, 1] and controls the time constant. Larger the faster the background adapts. Generally one should start by setting to a small number, like 0.001. The adaptive parameter can be throttled. In presence of high degree of change, or transients, should be set to zero so that the background does not pick up the transients; otherwise should gradually increase to 1 for speed up background learning.
is in the range of [0, 1] and controls the time constant. Larger the faster the background adapts. Generally one should start by setting to a small number, like 0.001. The adaptive parameter can be throttled. In presence of high degree of change, or transients, should be set to zero so that the background does not pick up the transients; otherwise should gradually increase to 1 for speed up background learning.
Foreground is the transients components of a scene, defined as the difference between instantaneous image  and the background, . The difference can be by simple subtraction:
and the background, . The difference can be by simple subtraction:

,
or by color-space difference:
or other metrics. Now, both background and foreground computation described above can be applied to both amplitude, color and depth images. In fact it is even possible to extend the above concept to a volume map.
Now, one can model background based on statistics. Such method requires collection of statistical data first to form a model of the background. Examples of these are included in the Reference section.
Finding Entities in the Foreground
Each foreground entity is evaluated for what it is and where it is. But what constitute an entity? An entity observed from  will have a blob or contour caused by the foreground-background subtraction; if a depth sensor is used, the contour would also contain depth discontinuity, which separates foreground from background. In other word, an entity in the foreground is one that has an enclosing contour of depth discontinuity.
will have a blob or contour caused by the foreground-background subtraction; if a depth sensor is used, the contour would also contain depth discontinuity, which separates foreground from background. In other word, an entity in the foreground is one that has an enclosing contour of depth discontinuity.
Using OpenCV, the foreground can be converted to a binary image using appropriate depth threshold. Then the binary image is cleaned up using morphological operators, such as open. The cleaned binary image is then passed into contour finding routine which will extract multiple contours. Each contour, together with the depth map, amplitude map and color image, can be used for object recognition.
Presence and Absence of Entities
Now the foreground from subtraction can be either presence or absence of entities. Again, if depth map is used, negative foreground means presence, and positive foreground means absence. Note: foreground objects are closer and will have lower depth values.
Once processed the foreground entity is encoded into the background, but the entity’swhere and what are remembered and associated. If foreground entity represents an absence of object, the hole created by the absence can be used to recall what was there.
Encoding the What and the Where
Foreground entity discovered by subtraction needs to be recognized for
what it is, and then associated to
where it is. The method described in the section,
Finding Entities in the Foreground is used to finding foreground blobs, each can have a centroid. The extent of the blob about the centroid
frames the object. The extents of the object can be normalized about its z-depth for range-invariant matching against pre-stored templates. For proper matching, the pre-stored templates are also framed by their extents and centroids. Since the object is framed in a normalized, spatial-invariant fashion, recognition becomes easier, the object’s spatial information needs to be encoded separately and associated with its framed memory. The object’s surface may also contain visible features that can play an important role in recognizing
what the object is. The centroid’s location relative to the robot’s own reference frame, together with the extents of the object, encodes
where the object is relative to the robot. Since the robot maybe situated in a room, so to express where the object is relative to the room will require double transformation. Knowing where the robot is relative to the room require algorithms such as
SLAM.
References
(The above article is solely the expressed opinion of the author and does not necessarily reflect the position of his current and past employers and associations)



